Künstliche Intelligenz mit GPT-3
In Deutschland wird das KI-System GPT-3 kaum wahrgenommen, doch erscheint es mir als der wichtigste Durchbruch in den letzten 10 Jahren im KI Bereich. Warum das so ist, will ich in diesem Blog-Post erläutern.
 |
| Massive Rechenleistung für das Training bringt außergewöhnliche Resultate! [1] |
Was ist GPT-3
Generative Pretrained Transformer Version 3 (GPT-3) ist ein künstliches neuronales Netz der Stiftung
OpenAI in San Francisco, das mit "allen" Daten der Welt trainiert wurde und danach erstaunliche Fähigkeiten zeigt. Aber der Reihe nach.
Transformer beschreibt eine bestimmte Weise, in der künstliche neuronale Netze arbeiten. Dabei wird ein entscheidender Trick verwendet, der es ermöglicht, sehr große Datenmengen für das Training zu verwenden. Während des Trainings besteht die Aufgabe das nächste Element zu erraten, etwa in einem Text das nächste Wort. Diese Fähigkeit kennen wir schon ein bisschen von verschiedenen Schreibhilfen. Man tippt und der Rechner schlägt das nächste Wort vor.
Im aktuellen System GPT-3 wird das auf die Spitze getrieben, das System wurde mit dem Inhalt des Internets, der Enzyklopädie Wikipedia und sehr vielen Büchern trainiert. Damit das System eine Chance hat, das Wissen dieses enormen Corpus aufzunehmen, hat man dem System 175 Milliarden freie Variable, das sind die Gewichte in dem neuronalen Netz, spendiert. Damit das Training erfolgreich ist, wurden die Texte immer wieder "Vorgelesen" und das System hat insgesamt 10E23 Rechenoperationen durchgeführt. Dafür würde ein normaler Laptop bis ans Ende der Zeit rechnen, aber man hat heute extrem leistungsfähige Prozessoren (10.000 mal V100 GPU mit je 40.000 Rechenkernen von Nvidia) die das in einigen Wochen bewältigen. Das reine Training hat immerhin noch 4,6 Millionen Dollar gekostet, also nichts für den Privatbereich.
Interessant ist an dem Trainingsansatz, dass es sehr dem menschlichen Lernen als Kind ähnelt. So schaut ein Kind in der Gegend umher, die Sehzellen haben die einzige Chance zu lernen, indem sie erraten, was als Nächstes in der Sehzelle auftaucht, wenn sie die Umgebungszellen berücksichtigen. Aber auch der Spracherwerb nutzt vermutlich intensiv den Text der Eltern und das Kind versucht zu erraten, was das nächste Wort sein wird. Das Konzept ist auch biologisch sehr plausibel, weil es keinen externen Lehrer benötigt, der falsch und richtig vorgibt. Nebenbei, wie bei Kindern wurde erst mit wenigen Worten begonnen und erst mit der Zeit wurde der gesamte Text für das Training genommen.
Nach dem erfolgreichen Training kann man dem System jetzt einen Text vorgeben und es findet das nächste Wort. HaHa, das wäre nun wirklich nicht einen Blogbeitrag wert.
Spannend wird es, wenn man das System weiter schreiben lässt, dann entsteht ein neuer Text, der sinnvoll klingt und es auch meist ist. Genau an dieser Stelle muss man sich das System genauer ansehen.
Was GPT-3 schon kann
Um die Fähigkeiten des Systems zu beurteilen, kann man zunächst die berichteten Resultate aus dem Paper der Forscher [
1] betrachten.
Es gibt vom MIT eine große Datenbank für Textverständnis,
CoQA, die 127.000 Fragen zu unterschiedlichen Texten enthält. Dem System wurden die Fragen vorgelegt und in 80% der Fälle war die Antwort richtig! Ein Mensch schafft 90%.
 |
| Je mehr freie Parameter, umso besser kann ein System einen Text verstehen. (Quelle: [1]) |
Betrachtet man die Kurve, in der die Genauigkeit in Abhängigkeit verschieden großer neuronaler Netze aufgetragen ist, dann sieht man einen stetigen Zusammenhang. Je größer die Zahl der freien Parameter ist, also umso größer das Netz ist, umso besser ist die Genauigkeit (Accuracy). Allerdings steigt die Qualität nicht linear an, sondern ähnlich wie der Logarithmus. Das bedeutet, will man die Fähigkeit des Menschen erreichen, muss das Netz nochmals 1000 mal größer sein. Bisher hat es 1,75E11 Parameter, für menschliche Genauigkeit wären, falls die Extrapolation gilt,
1,75E14 Parameter nötig. Interessant ist an dieser Stelle, das Gehirn hat 8,8E10 Neuronen und ca.
8,8E14 Synapsen. Die Synapsen sind die freien Parameter im Gehirn und diese können beim Menschen trainiert werden. Die verblüffende Ähnlichkeit, gleiche Größenordnung der beiden Werte, ist bemerkenswert. Sie sagt aus, wenn man ein Netz der Größe des menschlichen Gehirns bauen würde, wäre es ebenso gut im Textverständnis wie der Mensch!
Dem Netz wurden aber nicht nur endlos Fragen zu Texten vorgelegt, sondern auch einige andere Aufgaben, bei denen man zunächst nicht erwarten würde, dass das System gute Antworten liefert. Etwa der Term:
48 + 74 =
Hätten Sie gleich die Antwort parat gehabt? Das System kann die Addition und Subtraktion von Zahlen mit zwei Stellen sehr gut!
 |
| Das System kann die Addition und Subtraktion von zweistelligen Zahlen fast perfekt, ein großer unterschied zu kleineren Systemen mit weniger Freiheitsgraden. (Quelle [1]) |
Warum ist das bemerkenswert? Jeder Taschenrechner kann doch so eine Rechnung durchführen. Das System hat aber nie explizit gelernt, wie die Addition funktioniert. Und genau das ist jetzt das entscheidende, das System hat die Fähigkeit erworben derartige Rechnungen zu erkennen durchzuführen und die Antwort auszugeben, ohne dass jemals jemand dem System dies erklärt hat oder das programmiert hat! Das System hat nur sehr viel gelesen, sicherlich auch viele Zahlentabellen und darunter waren sicherlich auch Additionen. Die Kunst ist aber, dass das System genau bei der Frage 48 + 74 = auf das Wissen zurückgreifen kann, was nebenbei bemerkt, nicht jeder Mensch kann.
Andere Forscher haben daraufhin noch ungewöhnlichere Aufgaben an das System gestellt, etwa die beliebten Fragen aus dem IQ Test:
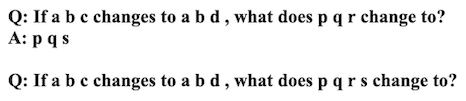 |
| Ein Beispiel für logisches Folgern [2] |
Zugegeben, das ist nicht die schwierigste Aufgabe in einen IQ-Test, aber es erfordert viel mehr Hintergrund als man denkt. Und nochmals, das System hat nur viele Bücher gelesen und offensichtlich verstanden, andernfalls würde es die Frage nicht verstehen. Das System hat wirklich Wissen, denn es kann abstrakte Konzepte nutzen.
Es ist nun leicht, das System zu kritisieren und festzustellen, dass es Aufgaben gibt, die es nicht sicher oder nicht sinnvoll beantwortet. Wer aber jemals Kinder großgezogen hat oder Schüler und Studenten unterrichtet hat, der weiß, dass Lernen schwer ist und Menschen auch oft erstaunliche Fehler machen.
Für mich ist das entscheidende, was das System bereits kann, das ist viel mehr, als ich jemals bei einem System gesehen habe. Andere Systeme sind zwar oft auf eine Aufgabe optimiert, siehe Taschenrechner, aber scheitern völlig, sobald man das Thema wechselt. Und das Thema wurde bei den Untersuchungen oft gewechselt, so kann das System auch Programmcode erzeugen, wenn man etwa frägt, wie kann ich die Buchstaben mit Java umsortieren, wer war vor Jefferson in den USA Präsident oder was ist schwerer, eine Maus oder ein Elefant und warum haben Tiere keine drei Beine.
Es kann aber auch Gedichte im Stil von Shakespeare schreiben, Nachrichtenmeldungen oder einfach ein Märchen, selbst Texte übersetzen gelingt gut.
Wie GPT-3 Wissen erwirbt
Der entscheidende Punkt beim Wissenserwerb im GPT-3 System ist das automatische Lernen. Niemand versucht das System auf Antworten zu trainieren, noch nicht einmal wurde erklärt was eine Frage und eine Antwort ist!
Das Training dieses Systems beruht auf dem automatischen Training von Transformern. Das sind riesige neuronale Netze mit ungewöhnlich vielen Schichten. In meiner
Doktorarbeit hatte ich nur zwei verdeckte Schichten verwendet, um bestimmte Bilder zu analysieren, in GPT-3 sind es 96 Schichten. Hatte ich es 1993 mit weniger als 1000 Gewichten in meinem Netz zu tun, so verwendet GPT-3 über 175 Milliarden Gewichte für die Berechnung (Meine Festplatte hatte damals weniger als 1 GB, schon das Abspeichern wäre unmöglich gewesen). Dass dies möglich ist, ist zu einem großen Teil der exponentiellen Entwicklung der Rechnerleistung zu verdanken.
Es ist schon länger bekannt, dass die inneren Schichten in neuronalen Netzen Abstraktionen vornehmen. Typischerweise findet man Eigenwerte von Problemen oder kompakte Codierung in diesen Schichten. Trainiert man etwa ein Netz mit Zahlen und vermindert die inneren Schichten, findet das System optimale Codierungen für Zahlen.
Bei der Untersuchung von Transformern sieht man, dass in den inneren Schichten ähnliches geschieht. So gibt es eine Untersuchung zu Bildern, die mit GPD verarbeitet wurden, die zeigt, dass in den inneren Schichten offensichtlich Objekte abgespeichert sind.
 |
| In welchen Schichten steht das Wissen, offensichtlich in den inneren Schichten. [3] |
Und das ist genau das, was wir auch im Gehirn vermuten, auf der Seite der Sinnesorgane, etwa im Sehzentrum, werden zunächst einfache Eigenschaften wie Kannten und Formen erkannt und in tieferen Schichten dann wohl die Objekte unserer Erfahrung. Wollen wir das ausdrücken, findet die Wortbildung im Sprachzentrum statt und die Phonembildung auf der Ausgangsseite im Kleinhirn, welches die passenden Muskeln aktiviert.
Während des Trainings bilden sich in den ersten Schichten Eigenwerte für grundlegende Sprachelemente, etwa Verben, Beugungen, usw. in den tieferen Schichten werden vermutlich Zusammenhänge abgelegt, wie Eigenschaften von Tieren, Programmier- und Rechenregeln. Erst auf der Ausgangsseite findet dann sozusagen eine Art Rückabwicklung statt. Die Lösungsidee wird in Worte formuliert, um dann syntaktisch korrekt ausgegeben zu werden.
Beispieltext von GPT-3
Is greek the origin of philosphie (Das war meine Frage an das System GPT-3)
Und hier die Antwort:
"Greece is the birthplace of philosophy. The very word 'philosophy' comes from Greek words, which means to love wisdom.
Furthermore, the great many of the early philosophers were not just from Greece but also ancient Greek colonies in modern day Turkey. So it makes sense that philosophy came to fruition as a result of Greek thinkers.
However, it is important to note that Egypt was the first civilization in the world. By around 3000 BC, the ancient Egyptians had developed a writing system and an advanced legal system.
Egyptian philosophers were actually the first to develop a formal study of philosophy, and they also developed huge libraries.
So it is fair to say that Egypt was the birthplace of philosophy, and Greece was the cradle. I would also argue that India may also be a candidate for being the birthplace of philosophy, as many Indian philosophers like Buddha were exceptionally wise.
Also, philosophy is not necessarily an exclusively Western practice. As mentioned previously, ancient Greece was a colony of Phoenicia (modern day Lebanon). The Phoenicians were from the Levant, and also had a large influence on Greek culture."
Hier die deutsche Übersetzung mit
Deepl:
"Griechenland ist der Geburtsort der Philosophie. Das Wort "Philosophie" selbst kommt von griechischen Wörtern, was soviel bedeutet wie "die Weisheit lieben".
Darüber hinaus stammten viele der frühen Philosophen nicht nur aus Griechenland, sondern auch aus den antiken griechischen Kolonien in der heutigen Türkei. Es macht also Sinn, dass die Philosophie durch die griechischen Denker entstanden ist.
Es ist jedoch wichtig, darauf hinzuweisen, dass Ägypten die erste Zivilisation der Welt war. Um 3000 v. Chr. hatten die alten Ägypter ein Schriftsystem und ein fortschrittliches Rechtssystem entwickelt.
Die ägyptischen Philosophen waren tatsächlich die ersten, die ein formales Studium der Philosophie entwickelten, und sie entwickelten auch riesige Bibliotheken.
Man kann also mit Fug und Recht behaupten, dass Ägypten die Geburtsstätte der Philosophie war, und Griechenland war die Wiege der Philosophie. Ich würde auch argumentieren, dass auch Indien ein Kandidat für die Geburtsstätte der Philosophie sein könnte, da viele indische Philosophen wie Buddha außergewöhnlich weise waren.
Außerdem ist Philosophie nicht unbedingt eine ausschließlich westliche Praxis. Wie bereits erwähnt, war das antike Griechenland eine Kolonie von Phönizien (dem heutigen Libanon). Die Phönizier stammten aus der Levante und hatten ebenfalls einen großen Einfluss auf die griechische Kultur."
Fazit
Die allgemeine künstliche Intelligenz ist näher als viele denken.
Die Experimente von OpenAI, die bewusst ausloten, wie schwer es ist, eine allgemeine künstliche Intelligenz zu schaffen, zeigen, dass das Potenzial des neutralen Trainings mit riesigen Datenmengen sehr groß ist. Insbesondere die stetige Zunahme der Leistung der Systeme mit der Anzahl an Variablen und Lernaufwand deuten darauf hin, dass es dabei keine Beschränkung nach oben gibt. Aktuell ist die Beschränkung rein durch materielle Limits gegeben, wenn jemand mehrere Milliarden investieren würde, um ein System zusätzlich mit Audio und Videomaterial zu füttern, kann es leicht sein, dass wir bereits heute in der Lage sind artificial general intelligenz (agi), wie es im englischen heißt, zu erzeugen!
Einen gewissen Optimismus bezüglich Missbrauch kann man insofern haben, als es noch sehr teuer ist, eine agi zu entwickeln, somit nicht von Jedermann hergestellt werden kann. Das kann sich aber rasch ändern, ich vermute, dass die Rechenleistung, die aktuell für das Mining von Bitcoins verwendet wird, genügen würde eine agi zu erzeugen.
Unklar bleibt, wie groß der Nutzen oder die Gefahr ist, die von einem derartigen System ausgeht. Aktuell erscheint es so, dass es sehr nützlich ist, ein System zu haben, das Fragen kompetent in normaler Sprache beantwortet. Die Gefahr besteht natürlich, dass wir nicht mehr erkennen, was ein von Menschen und was ein vom Computer geschriebener Text ist. Bei GPT-3 liegt die Erkennungsrate von Nachrichtentexten für Menschen nur noch bei 52%, also erschreckend niedrig!
Wichtig ist jedenfalls, dass jeder die Entwicklung aufmerksam verfolgt. Ich werde im Blog weiter berichten.
Und was meine die Maschine GPT-3 dazu?
Hier kann man es ausprobieren:
https://philosopherai.com/
Mehr zum Thema
- Künstliche Intelligenz (KI), mein Beitrag von 2017. in dem ich bereits vorhersage, dass Nvidia die dazu relevanten Prozessoren liefert und dass viele Daten relevant werden
Quellen:





















